
使用numpy实现反向传播算法示例

使用numpy实现反向传播算法示例
flowwalkerHW1:使用numpy实现反向传播算法示例
注:以往届 AI 基础作业为资料、采用任务驱动型方法进行学习
作业内容:
- 阅读并理解代码
- 修改 np_mnist_template.py,更改 loss 函数、网络结构、激活函数、完成训练 MLP (多层感知机,Multilayer Perception)网络以识别手写数字 MNIST(modified national institute of standards and technology)数据集
代码理解
numpy 数值调用库(相当于#include)
1 | import numpy as np |
使用np.array以支持矢量化运算如np.array[1,2]+np.array[3,4]
1 | X=np.array([0,0,1],[0,1,1],[1,0,1],[1,1,1]) |
神经元模型
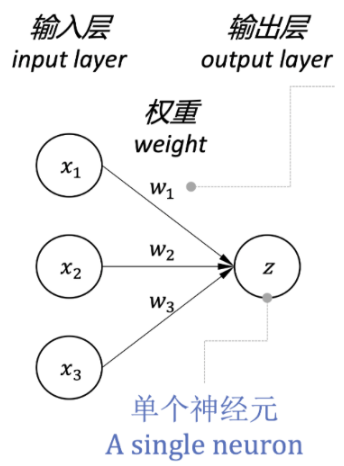
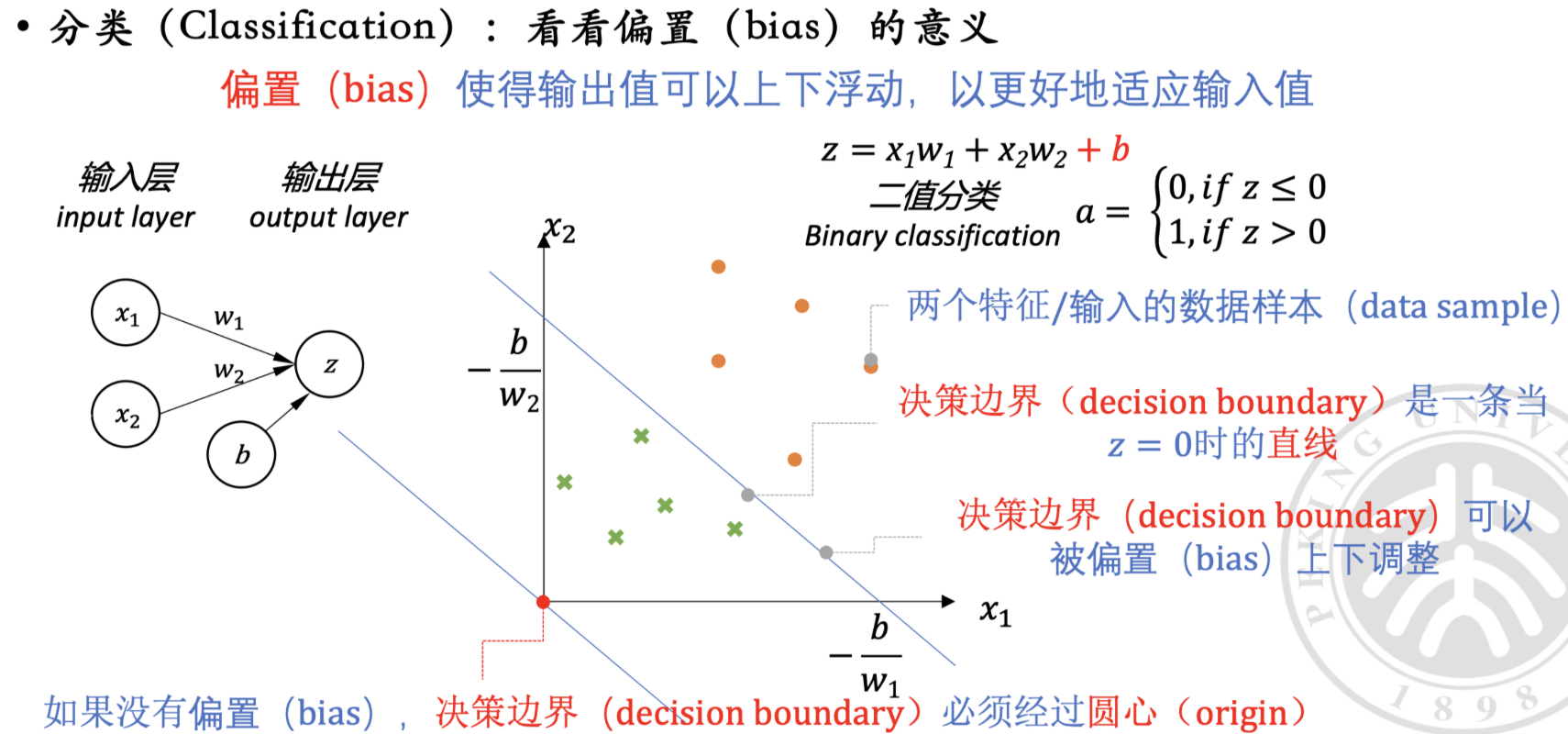
关于偏置
定义激活函数及其导数
1 | def sigmoid(x): |
初始化神经网络参数–填充随机数的矩阵
1 | def getweights(shape=()): |
定义网络结构
1 | class Network(object): |
首先定义构造函数(初始化方法)
初始化方法范式
1
2
3
4class ClassName
def __init__(self,parameter1,parameter2,...):
self.attribute1=parameter1
self.attribute2=parameter2如何理解这个self:简单理解为相当于其定义的变量为c中该对象的成员变量(c中显示的this指针)
lr=learning rate学习率
1 | def __init__(self,lr=0.01): |
接下来定义实现传播算法
1 | def backward(self,X_batch,y_batch): |
反向传播算法
1
# ...见第二模块专门详解
结束对象,最后主函数
1 | if __name__=="__main__": |
此处提到batch即一次训练送进去的数据,此处为4也即batch size(batch:批,次)
重磅理解:反向传播算法
算法框架
1 | def backward(self,X_batch,y_batch): |
反向传播算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#初始化计数器
batch_size=0 #初始化实际处理的个数
batch_loss=0 #初始化累计本批次样本所产生的总误差
batch_acc=0 #记录预测正确的样本个数 acc:accuracy
#grads:gradients 梯度
#此处顺序开始相反:反向意味(从输出往输入)
self.grads_W2=np.zeros_like(self.W2)
self.grads_b2=np.zeros_like(self.b2)
self.grads.W1=np.zeros_like(self.W1)
self.grads_b1=np.zeros_like(self.b1)
#zeros_like:创建一个形状完全一样但是全0的矩阵
#...计算梯度,见下
#梯度平均
self.grads_W2/=batch_size
self.grads_b2/=batch_size
self.grads_W1/=batch_size
self.grads_b1/=batch_size
#loss 平均
batch_loss/=batch_size
#准确率平均
batch_acc/=batch_size
#输出训练状态
print("loss:{} batch_acc{} batch_size{} lr:{}".format(batch_loss.batch_acc,batch_size,self.lr))
#更新参数
self.W2-=self.lr*self.grads_W2
self.b2-=self.lr*self.grads_b2
self.W1-=self.lr*self.grads_W1
self.b1-=self.lr*self.grads_b1
其中字符串格式化语法:
语法:
"模式字符串".format(变量 1,变量 2,……)组件:
{}占位符.format把变量名按顺序填入占位符
计算梯度
注:zip打包函数:**zip(X_batch,y_batch)把两个序列对应的元素逐一打包
1 | for x,y in zip(X_batch,y_batch): |
loss函数专讲(数学演绎)
…












