
Python修养1

Python修养1
flowwalkerPython修养1
思想:
换行当
;缩进当{}
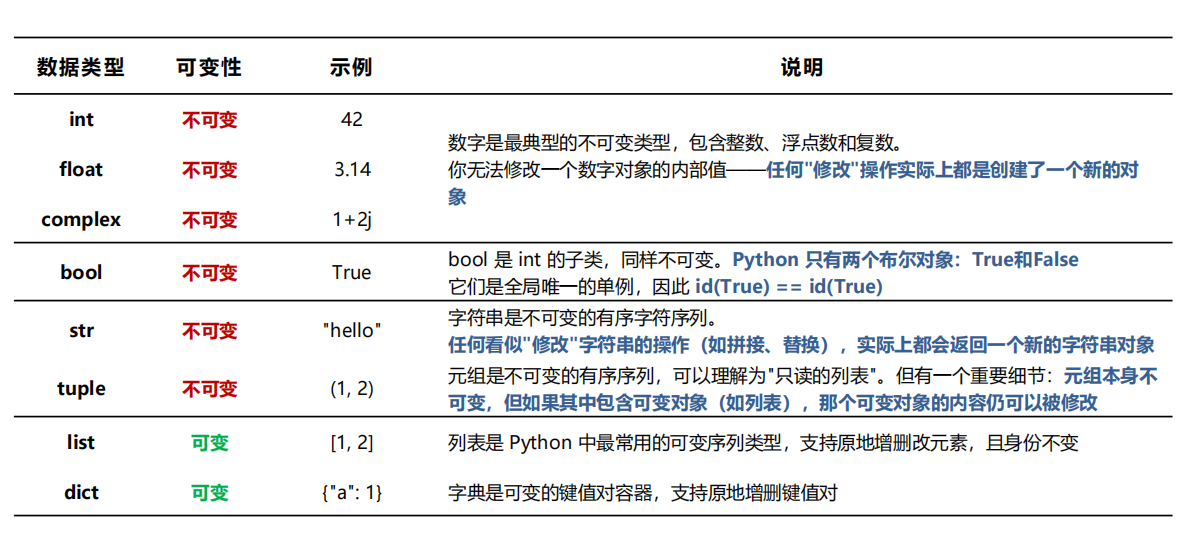
对象三属性
- 值: 可变/不可变
- 身份: 内存唯一地址,严格只读
- 类型( 可用
type(you_want)来读取)
每个变量都相当于指向某个对象的引用
引用对象可变, 则可以通过变量修改
引用对象不可变,则只能让变量指向另一个新对象
⚠️python里的
=永远是指向对象操作而非拷贝a=b指向同一个对象对象可变且做原地修改, 原地改动
🌊对象不可变且做了"修改"操作, 必须创建新的对象
a=a+b创建新对象, a然后指向他a+=b原地修改,a不指向新对象
关于注释:
- 单行
# - 多行
command+/
- 单行
关于赋值的随意性
s1,s2,s4,s3=s4,s3,s2,s1关于变量
不需声明, 使用前必须赋值
类型可变
没有
double( 或者说double就叫float), 多了complex和tuple和dict,string叫str, 列表叫list——类型名相当于类名1
2a=str()
b=1+2j元组本身不可变, 但是⚠️其中可变对象元素仍可变
关于运算符
**表示幂运算关于布尔类型
注意是
True和False, 大小写有规范0空strtuplelistdist都相当于False( 但不是等于)1
2
3
4
5
6
7
8if not ():
print ("ok") # ok
if not {}:
print ("ok") # ok
if not "":
print ("ok") # ok
if not []:
print ("ok") # okTrue可以看作1,False可以看作0
1
2
3
4
5
6True == 1 #True
False == 0 #True
"" == False #False
2 == True #False
[] == False #False
[2,3] == True #False关于逻辑运算符
注意是
and和or和not关于类型转换函数
⚠️
repr(x)将x转换为字符串表达式, 注意类型是字符串chr(x)将x转换为对应ASCII码字符ord(x)将字符转换为整数编码值(16位)1
2
3print(repr(12.334)) # 12.334
print(str("hello")) # hello
print(repr("hello")) # 'hello'列表和字符串的转换
语法:
<str> = <separator>.join(<list>)1
2
3
4
5newstr = list('abcdafg')
print(newstr) # ['a', 'b', 'c', 'd', 'a', 'f', 'g']
newstr[4] = 'e'
str = ''.join(newstr) #列表到字符串转换
print(str) # abcdefgint(x)不会把x变成整数⚠️
eval(x)把字符串x看做一个表达式求其值理想情况下
eval(repr(x))=x
目录
[TOC]
关于运算符
运算符中只要有一个操作数是小数结果就是小数, 若需要结果整数, 需要额外强制转换
使用
/即使整除也是浮点数//整除向下取整,而非向零(c++向0)
关于循环
1 | for <变量> in <序列>: |
1 | while <逻辑表达式>: |
- 没有
switch - <序列>可用
range生成 pass表示什么都不做, 占位;continue和break同用
关于print
print(s,end=" ") 缺省情况end='\n'
简单构造字符串: “xxxx %s xxxx %(s)”
关于is和==的区别
a is b为True说明a和b指向同一个地方a==b为True则说明放的东西相同,不一定指向同一个地方
a=b使得a和b指向同一个地方
⚠️一般需要:
用
==比较值用
is比较是否同一个对象=会导致变量别名, ⚠️一个赋值给另一个, 两个变量将指向同一个对象, 修改任何一个都会影响另一个
为了复用同一个对象, 常常有驻留,
is难预测→对于**不可变类型只需关注==, 不得用is判断值是否相等 **推荐使用
is的场景
if x is None
小整数有缓存机制, 元组一般没有驻留( 小整数可能会)
关于整数类型
任意长
- 0b前缀表示二进制
- 0o前缀表示八进制
- 0x前缀表示十六进制
可以使用例如12.99.is_integer()来判断是否整数
查询是否是某个类型
isinstance(<变量名>,<type>)
关于浮点数相等的判断
⚠️用equal_float判断
1 | import sys |
想看看
sys.float_info可以
2
print(sys.float_info)此外
2
3
4
5
6
x = 123.50
print(round(x)) #不精确,如print(round(119.49999999999999999)) => 120
print(math.floor(x))
print(math.ceil(x))
print(12.3.is_integer())
关于输入和输出
关于
input(<问候语>)- 输出问候语, 读取输入的字符串, 需要强制类型转换才能当数字用
一行多输入
1
2
3
4
5lst=input().split()
x,y,z=int(lst[0]),lst[1],int(lst[2])
# x,z是整数,y是字符串
# ...
# split函数内部可以指定分割符如",."表示以",."为分割符而⚠️不是其中任意字符split(s)开头和结尾有非缺省分割符的字符串列表会额外输出空串( 缺省情况下智能合并连续分割符并忽略开头和结尾分割符)
输入输出的重定向
1
2
3
4
5
6
7
8
9import sys
f=open("t.txt","r")
g=open("d.txt","w")
sys.stdin=f
sys.stdout=g
s=input()
print(s)
f.close()
g.close()x.split()的值是一个列表, 包含字符串经过空格, 制表符, 换行符分隔得到的所有子串, 但是input默认情况下只读一行
关于字符串
*可以构成重复字符串
⚠️重点
赋值
单引号\双引号\三引号 皆可
其中三双引号可以包含换行符\制表符\特殊符号
字符串太长
1
2
3print("this \
is \
good")太长了使用
()或\1
2
3
4
5
6if a>3 and \
a<9:
print('ok')
if(a>3 and
a<9):
print('ok')
访问
变量[序号或切片]访问子串
完成切片语法
x[start:stop:step]
1 | x="aggfdfd" |
⚠️字符串是不可修改的
如果确实需要,应先转换为列表
2
3
4
5
6
7
s[0] = "z" # 可以改
"".join(s) # "zbc"
#否则
s="kskksk"
s[1]="d" #error
输出不转义字符
print(r'ab\ncd')
判断子串
in
not in
正常语言即可
print("hello" in s)
字符串函数
count求解子串出现次数len求解字符串长度其他的
s.upper(),s.lower(),s.isdigit()(是否全为数字)s.startwith(),s.endwith()s.find(want)找不到返回-1,s.index(want)抛出异常s.replace(target_index,replacement)
s.strip(s)除去两端空格,\r,\t,\ns.lstrip(s)除左端s.rstrip(s)除右端s缺省情况下为空白字符, 指定情况下为s中的所有字符
用多个字符分割
格式:
re.split(pattern,string)
pattern: 匹配的正则表达式
string: 要匹配的字符串
1 | import re |
正则
;| |,|\*|\n表示遇到 分号、空格、逗号、星号、换行 都要切一刀。字符串的编码在内存中的编码是unicode的。没有字符类型
2
3
4
print(ord("好"))
print(chr(22900))
print(chr(97))
🌊以下为AI整理, 若有时间需勤加复习
字符串格式化
1 | # % 格式化: %s字符串 %d整数 %f浮点数 %.nf保留n位小数 |
⚠️**%.nf 不是四舍五入,是"四舍六入五成双"**
- ≤4 舍去,≥6 进一
- 5 看前面数字奇偶:前为奇则进,前为偶则舍;5后面还有有效数字则一定进
1 | print("%.2f, %.2f" % (5.225, 5.325)) # 5.22, 5.33 |
关于字符编码
- ASCII:1字节,只表示英文、数字、标点(如
'a'是0x61) - GB2312/GBK:兼容ASCII,中文用2个最高位为1的字节表示
- Unicode:内存编码,几乎涵盖所有文字,每个字符2字节(个别4字节);Python字符串即Unicode
- UTF-8:可变长(1-6字节),英文1字节、中文通常3字节;文件存储/网络传输一般用UTF-8
1 | print(ord('好')) # 22920 Unicode码点 |
⚠️UTF-8文件开头可能有3字节标记 BOM(EF BB BF),记事本能正常显示,但C用 cin 读取会出错。C需用 _wfopen(L"utf8.txt", L"r,ccs=utf-8") 之类方式读取。
关于字符串与字节流
Python字符串是Unicode,要保存到文件或发送需编码为字节流;读取时自动/手动解码:
1 | s = 'ABC好的' |
关于源程序编码
Python 3 默认认为 .py 源文件是 UTF-8 编码(且期望有BOM)。如果源文件实际是GBK且无编码声明,运行报错:
1 | SyntaxError: Non-UTF-8 code starting with '\xb7' in file testansi.py... |
解决办法:在源文件第一行或第二行加声明
1 | # -*- coding: GBK -*- |
PyCharm编写的
.py文件默认就是UTF-8,一般无需额外声明。
C++与Python字符串对比
| 特性 | C++ std::string | Python str |
|---|---|---|
| 可变性 | 可变(可直接改 s[0]='H') | 不可变(修改需创建新对象) |
| 越界访问 | 需手动注意,可能崩溃 | 自动抛异常 |
| 引号 | 双引号(单引号是char) | 单/双/三引号均可 |
| Unicode | 需std::wstring或第三方库 | 原生支持 |
| 空值 | "" | "" 或 None |
| 性能 | 直接操作内存,快 | 因不可变性+GC稍慢,但开发效率高 |
操作语法差异:
1 | # 初始化 |
关于错误日志
1 | try: |
lambda表达式
lambda 参数1,参数2,...: 返回值
配合map
ls=list(map(lambda x:x*2,ls))
配合reduce
result=reduce(lambda x,y:x+y,ls)






