自动化数据清洗实践项目总结
前言
本工具专为WGM海量聊天记录自动化总结打造,基于Python开发,结合DS 大模型API实现智能总结,通过滑动窗口算法解决长文本处理限制。提示词仅要求核心情报以表格格式、分类别呈现,本文简单说明并记录一下工具的Python代码模块化实现逻辑。
目录
[TOC]
一、工具整体架构
工具采用模块化编程思想,分为5大核心模块:
- 依赖库导入模块
- 全局配置模块
- 核心功能函数模块
- 主流程执行模块
- 程序入口初始化模块
整体流程:读取WGM原始记录 → 解析单条消息 → 滑动窗口切片 → 调用DS API生成总结 → 输出Markdown结果。
二、Python代码模块化实现(核心)
模块1:依赖库导入
1
2
3
4
5
|
import os
import time
import re
|
实现说明:
- 仅正式调用DS API时延迟导入
openai; - 正则库是解析WGM聊天记录的核心,用于识别消息开头
模块2:全局配置模块
统一管理所有固定参数、文件路径、运行模式、算法参数,便于后期修改与维护。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
BASE_DIR = "xxxxx"
SOURCE_FILE = os.path.join(BASE_DIR, "value.txt")
PROMPT_FILE = os.path.join(BASE_DIR, "main/PromptV1.md")
OUTPUT_FILE = os.path.join(BASE_DIR, "summary_result.md")
TEST_OUTPUT_FILE = os.path.join(BASE_DIR, "test_summary_result.md")
TEST_CHUNK_FILE = os.path.join(BASE_DIR, "test_chunk_check.txt")
CHUNK_SIZE = 1000
OVERLAP = 200
STEP = CHUNK_SIZE - OVERLAP
TEST_MODE = False
TEST_MESSAGES_LIMIT = 50
TEST_CHUNK_SIZE = 10
TEST_OVERLAP = 3
MESSAGE_HEADER_PATTERN = re.compile(r'^.*?\(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\):')
|
实现说明:
- 路径配置:使用
os.path.join保证跨系统路径兼容性,所有文件统一管理; - 滑动窗口:解决WGM长记录无法一次性传入DS API的问题,重叠设计避免上下文断裂;
- 测试模式:独立参数,不影响正式运行,快速验证逻辑;
- 正则规则:精准匹配WGM标准消息头,为消息解析提供规则支撑。
模块3:核心功能函数模块
包含两个核心函数,分别实现WGM消息解析和DS API调用,是工具的核心逻辑。
子模块3.1:WGM聊天记录解析函数 parse_chat_records
功能:将按行读取的WGM原始文本,拼接为完整单条消息,避免跨行消息被拆分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def parse_chat_records(lines):
"""
原始聊天记录行解析:转换为单条消息列表
参数:lines (list): WGM原始行列表
返回:list: 完整单条消息列表
"""
messages = []
current_message = []
for line in lines:
clean_line_for_match = line.lstrip()
if MESSAGE_HEADER_PATTERN.match(clean_line_for_match):
if current_message:
messages.append("".join(current_message))
current_message = [line]
else:
if current_message:
current_message.append(line)
if current_message:
messages.append("".join(current_message))
return messages
|
实现说明:
- 遍历WGM每一行文本,通过正则判断是否为新消息开头;
- 跨行消息自动拼接,100%保留WGM消息原始完整性;
- 最终返回结构化的消息列表,为后续滑动窗口切片做准备。
子模块3.2:DS API调用函数 get_api_response
功能:封装DS API请求逻辑,支持测试模式(模拟返回)和正式模式(真实调用)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def get_api_response(prompt, content, is_test=False):
"""
调用DS API生成WGM记录总结
参数:prompt(提示词), content(待总结内容), is_test(测试模式)
返回:str: 总结文本
"""
if is_test:
return f"[模拟总结] 本批次包含 {len(content.splitlines())} 行内容,消息解析正常。"
from openai import OpenAI
client = OpenAI(
api_key="你的API Key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "system", "content": prompt}, {"role": "user", "content": content}],
temperature=0.3
)
return response.choices[0].message.content
|
实现说明:
- 测试模式:模拟API返回,快速验证流程,节省DS调用额度;
- 正式模式:严格遵循提示词要求,让DS输出表格格式、分类别的WGM总结;
模块4: main
程序核心调度模块,串联所有功能,实现完整的WGM总结流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
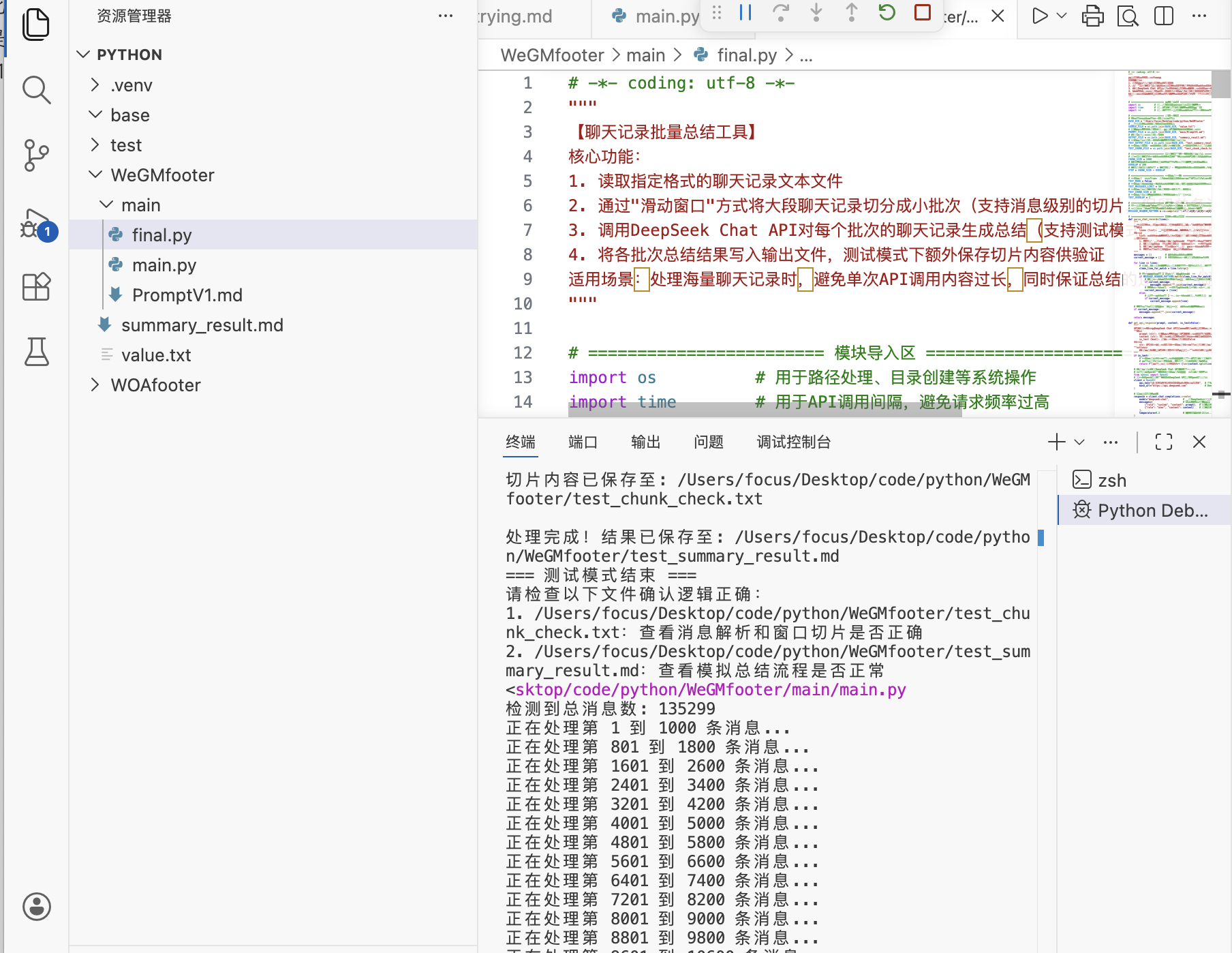
| def main():
"""主执行流程:加载配置→解析WGM→切片→调用API→写入结果"""
try:
with open(PROMPT_FILE, 'r', encoding='utf-8') as f:
system_prompt = f.read()
except (FileNotFoundError, Exception) as e:
print(f"提示词加载失败:{e}")
return
try:
with open(SOURCE_FILE, 'r', encoding='utf-8') as f:
raw_lines = f.readlines()
except (FileNotFoundError, Exception) as e:
print(f"WGM文件加载失败:{e}")
return
all_messages = parse_chat_records(raw_lines)
total_messages = len(all_messages)
print(f"✅ 检测到WGM总消息数: {total_messages}")
if TEST_MODE:
test_messages = all_messages[:TEST_MESSAGES_LIMIT]
current_chunk_size = TEST_CHUNK_SIZE
current_overlap = TEST_OVERLAP
current_step = current_chunk_size - current_overlap
current_output_file = TEST_OUTPUT_FILE
chunk_check_file = open(TEST_CHUNK_FILE, 'w', encoding='utf-8')
else:
test_messages = all_messages
current_chunk_size = CHUNK_SIZE
current_overlap = OVERLAP
current_step = STEP
current_output_file = OUTPUT_FILE
chunk_check_file = None
with open(current_output_file, 'w', encoding='utf-8') as out_f:
if TEST_MODE:
out_f.write("# 测试模式WGM总结结果\n\n")
for i in range(0, len(test_messages), current_step):
chunk_messages = test_messages[i : i + current_chunk_size]
chunk_text = "\n\n".join(chunk_messages)
start_idx = i + 1
end_idx = i + len(chunk_messages)
print(f"🔄 处理WGM第 {start_idx} - {end_idx} 条消息")
if TEST_MODE and chunk_check_file:
chunk_check_file.write(f"=== WGM消息批次 {start_idx}-{end_idx} ===\n{chunk_text}\n\n")
try:
summary = get_api_response(system_prompt, chunk_text, is_test=TEST_MODE)
out_f.write(f"### WGM批次 {start_idx} - {end_idx}\n{summary}\n\n{'-'*50}\n\n")
out_f.flush()
except Exception as e:
print(f"❌ 批次处理失败:{e}")
continue
if i + current_chunk_size >= len(test_messages):
break
if not TEST_MODE:
time.sleep(1)
if TEST_MODE and chunk_check_file:
chunk_check_file.close()
print(f"\n✅ WGM总结完成!文件:{current_output_file}")
|
实现说明:
- 异常处理:全覆盖文件读取、API调用异常,单个批次失败不影响整体流程;
- 模式自适应:自动切换测试/正式模式参数,适配调试与生产环境;
- 滑动窗口切片:按步长遍历WGM消息,保证大文本高效处理;
- 结果写入:实时刷新缓冲区,避免结果丢失,输出标准Markdown格式。
模块5:程序入口初始化
1
2
3
4
5
6
7
8
9
| if __name__ == "__main__":
"""程序入口:初始化目录 → 执行主流程"""
for path in [OUTPUT_FILE, TEST_OUTPUT_FILE, TEST_CHUNK_FILE]:
dir_path = os.path.dirname(path)
os.makedirs(dir_path, exist_ok=True)
main()
|
说明:
- 自动递归创建目
exist_ok=True 避免重复创建目录报错
三、关键运行配置说明
- 基础配置:修改
BASE_DIR为本地项目路径,替换DS API Key; - 模式切换:
TEST_MODE=True 开启测试,快速验证逻辑;False 正式处理WGM; - 滑动窗口:根据WGM消息量调整
CHUNK_SIZE和OVERLAP,适配DS API长度限制;
四、简单来说,
通过模块化Python代码可以简单实现了WGM海量聊天记录的批量智能总结:
- 正则解析保证WGM消息完整性;
- 滑动窗口解决长文本处理瓶颈;
- 自动输出表格格式、分类别的总结结果;
- 完整异常处理与资源管理
备注:最终输出格式化大致展示
PKU 25xkpool WGM提取总结笔记
核心信息
| 类别 | 关键情报摘要 | 涉及对象/地点 | 重要/紧迫程度 | 原始语境参考 |
|---|
| 学术机会与预警 | 竞赛3月20日补报名 | 信科 | ★★★★★ | 内部通知 |
| 课程红黑榜 | 思修植物系老师给分严、作业量大 | 思修、植物系老师 | ★★★★☆ | 学长提醒避坑 |
| 课程红黑榜 | 地概zkc老师讲课好、给分友好 | 地概 | ★★★☆☆ | 群友一致好评 |
| 课程红黑榜 | 简量wb老师课程评价两极分化 | 简量 | ★★★☆☆ | 群内观点争议 |
| 校内生活经 | 健身房/食堂使用技巧;W小程序办校园卡 | kml、农园食堂、W小程序 | ★★★☆☆ | 群友生活分享 |
| 风险防范 | 软件捆绑插件 | 信科作业、课程软件 | ★★★★★ | 助教通知+群友提醒 |
| 专业手段与科技讯息 | DS工具高效做数据可视化;校内论坛领教程 | DS工具、校内论坛 | ★★★★☆ | 技术分享+传闻 |
成书效果: